Pour exécuter des scénarios de test de charge créés avec des paramètres de contexte, nous utilisons des fichiers CSV comme un ensemble de données externes qui stocke les valeurs des paramètres (Téléchargement de variables dynamiques (paramètres de contexte) dans le scénario de test). Vous pouvez rendre votre test de charge plus réaliste en configurant l’utilisation des lignes de valeur à partir du fichier CSV téléchargé. Pour ce faire, accédez à la page Scénario de test dans la section Paramètres de contexte et configurez les options Plage de lignes de valeur et Utilisation de ligne.
Définition de la plage de lignes de valeur
Par défaut, toutes les lignes de valeur du fichier CSV téléchargé seront utilisées dans le test. Toutefois, dans le champ Plage de lignes de valeur, vous pouvez spécifier explicitement la plage dans laquelle vous souhaitez sélectionner des valeurs. La première ligne du fichier CSV qui contient des valeurs de paramètre de contexte est considérée comme la première ligne de valeur. La ligne avec les noms de paramètres n’est pas comptée.
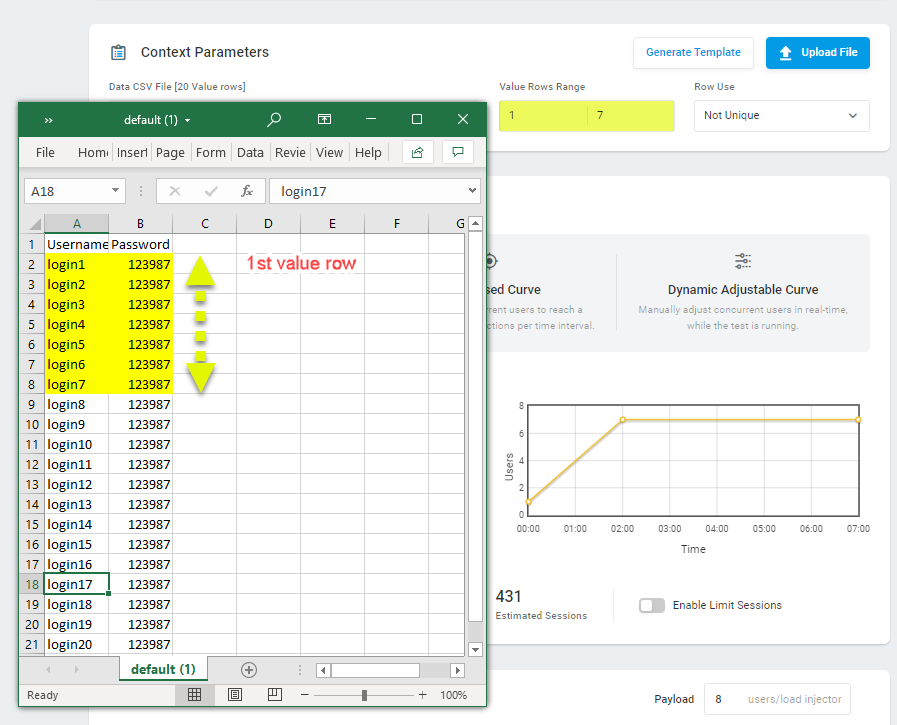
Définition du mode d’utilisation des lignes
Dans le champ Utilisation des lignes, vous pouvez spécifier comment les lignes de valeur du fichier CSV seront accessibles dans le test.
- Par défaut, le mode Non unique est utilisé et les lignes sont accessibles dans un ordre aléatoire.
- En règle générale, lorsque votre application Web ne permet pas d’utiliser les mêmes données simultanément (par exemple, la connexion simultanée n’est pas prise en charge), il est recommandé d’utiliser le mode Unique par utilisateur.
- Dans le cas où il est nécessaire de tester de charge avec des utilisateurs uniques en utilisant des données uniques (par exemple, pour se connecter à chaque fois sous un nouveau nom d’utilisateur), il est recommandé d’utiliser le mode Unique par session.
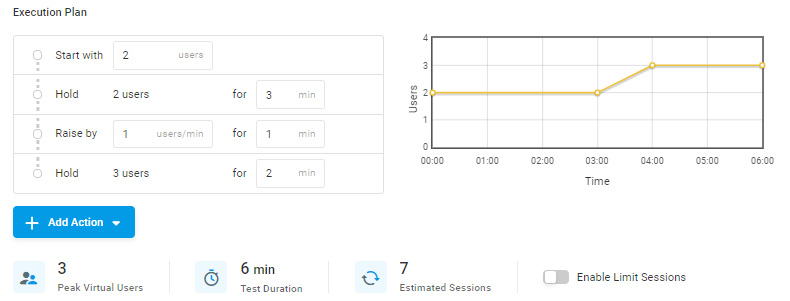
Par exemple, considérons un test de charge de base. Le plan d’exécution présenté dans l’image ci-dessous a une durée de périphérique de 2 minutes (le temps qu’il faut à un seul utilisateur pour exécuter une session de test).
Ensuite, examinons de plus près le mode d’utilisation des lignes et la façon dont le système utilise un fichier CSV pour exécuter le test décrit dans chaque mode.
Pas unique
Par défaut, le système sélectionne et transmet une valeur aléatoire à un utilisateur virtuel chaque fois qu’un utilisateur virtuel démarre une session de test. Dans ce cas, les valeurs d’une seule ligne peuvent être utilisées simultanément par différents utilisateurs (voir « Ligne 4 » sur l’image ci-dessous) et plusieurs fois par le même (voir « Ligne 1 » ci-dessous) ou différents utilisateurs virtuels au cours d’une série de tests.
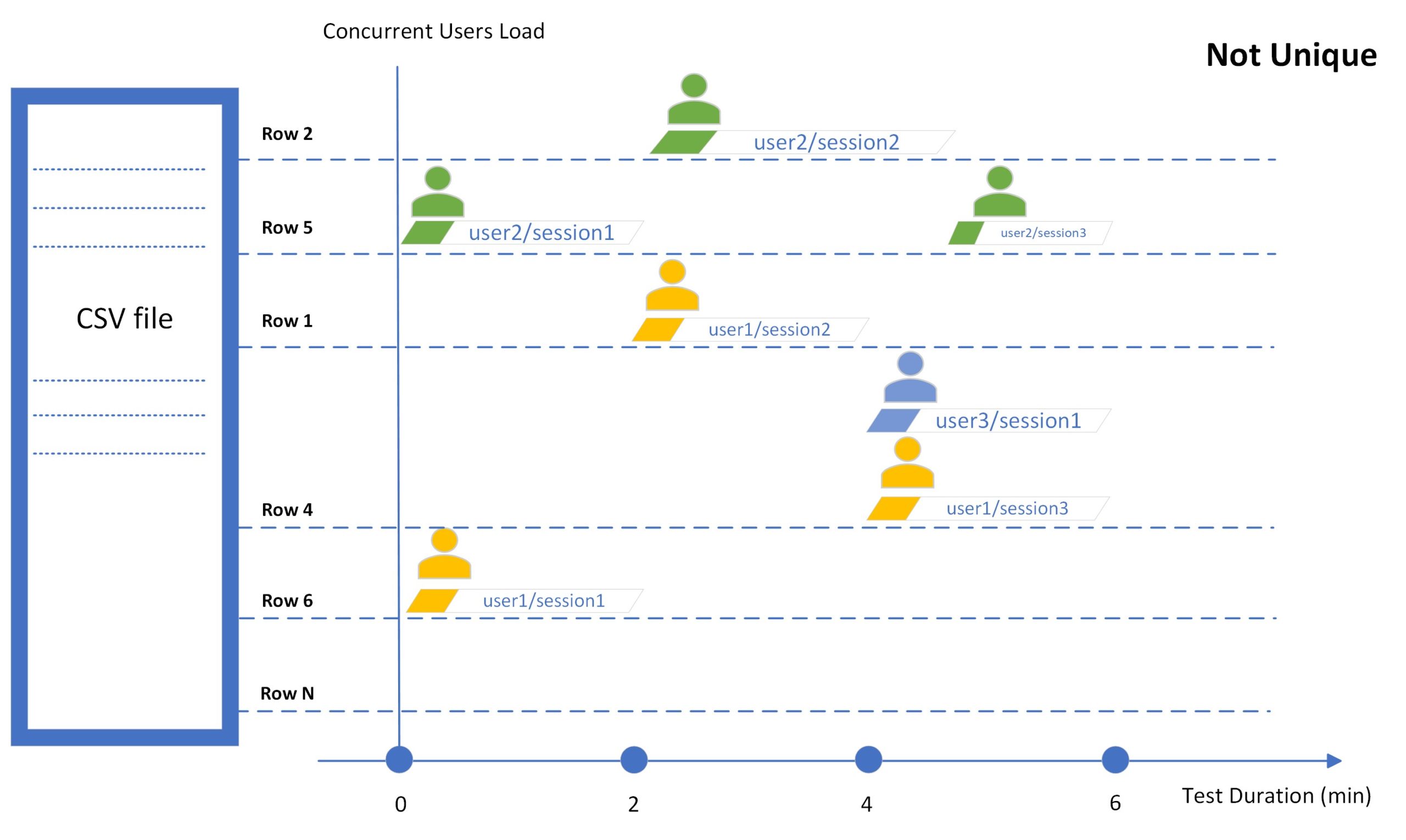
Si vous définissez la plage de lignes sur une ligne, toutes les sessions de test seront exécutées à l’aide de valeurs de la même ligne au cours d’une série de tests. Par exemple, tous les utilisateurs virtuels utiliseront le même nom d’utilisateur pour exécuter des transactions d’inscription ou le même mot-clé pour exécuter des transactions de recherche.
Unique par session
En mode Unique par session, le système utilise une ligne de valeur unique par session de test. Par conséquent, chaque ligne de valeur ne sera utilisée qu’une seule fois au cours de la série de tests.
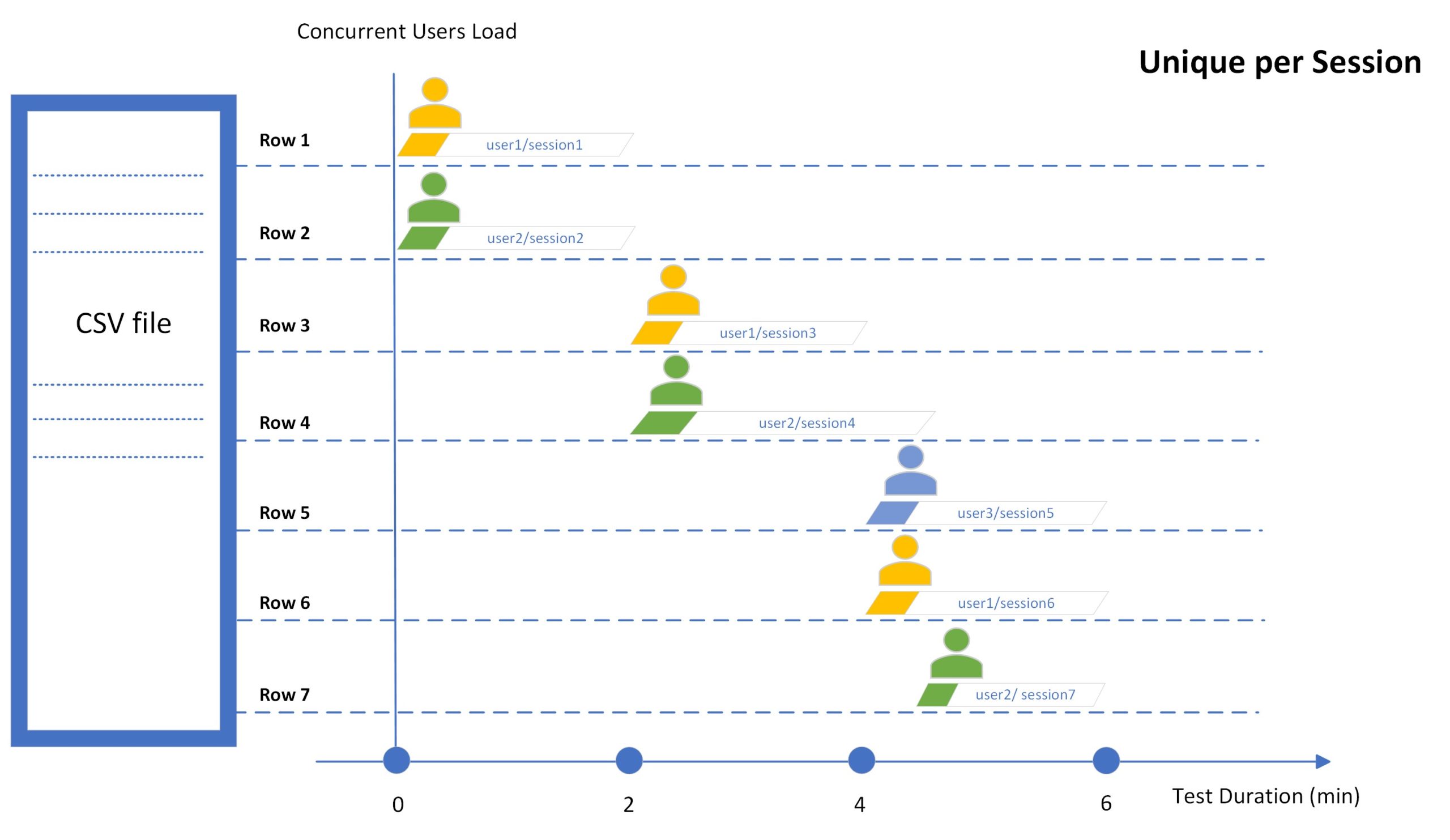
Notez que lorsque le mode Unique par session est sélectionné, le nombre de sessions dans le test sera automatiquement limité au nombre de lignes de valeur dans le fichier CSV téléchargé ou à la plage de lignes de valeur, le cas échéant (voir l’article Limitation du nombre de sessions de test).
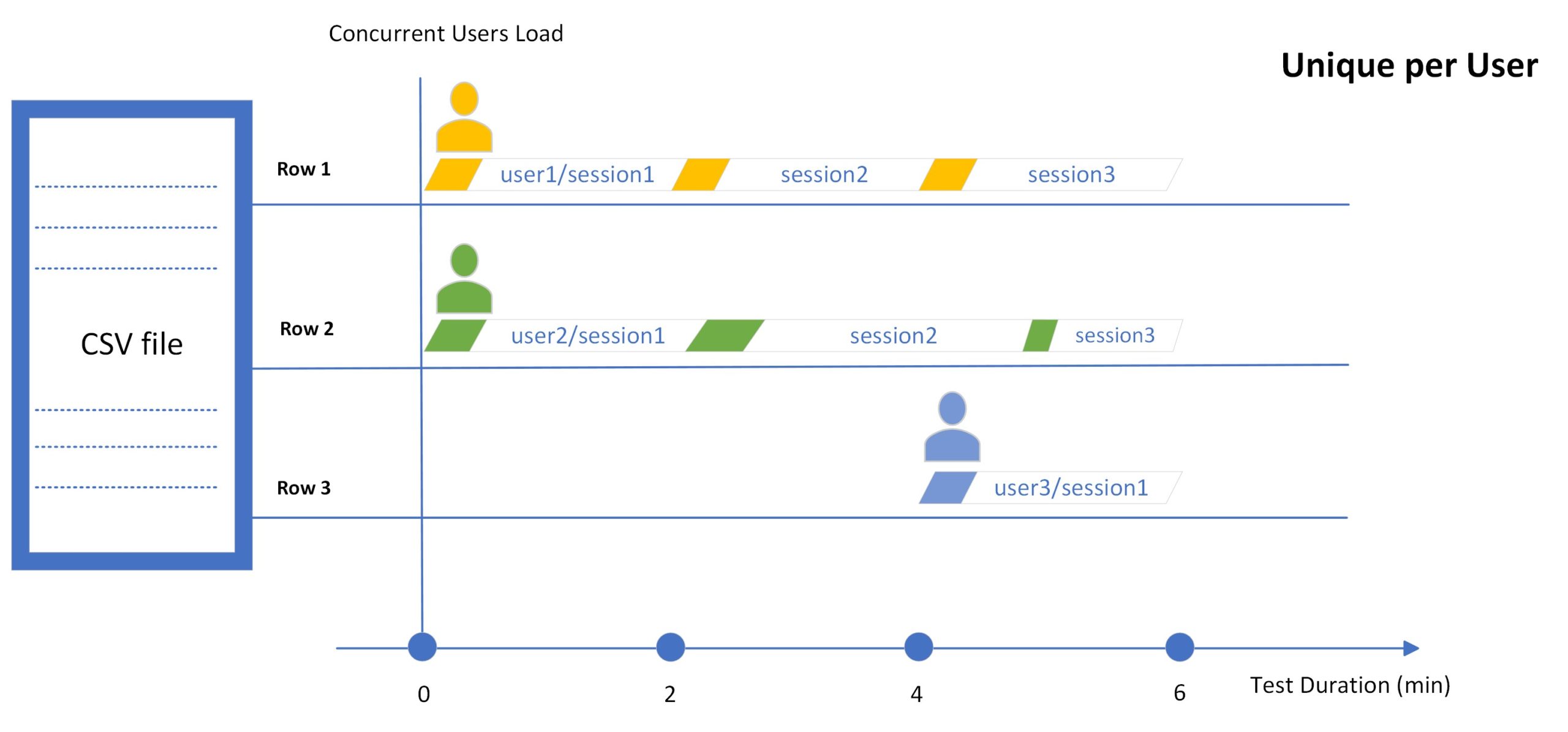
Unique par utilisateur
En mode Unique par utilisateur, le système utilise les valeurs d’une ligne unique uniquement avec un utilisateur virtuel au cours d’une série de tests. Notez que dans ce mode, le nombre d’utilisateurs virtuels sera limité au nombre de lignes de valeur dans le fichier CSV ou à la plage de lignes de valeur si spécifié.