Web 開発者や IT チームのメンバとして、Web サイトのパフォーマンスや、Web サイトと業界全体の他のユーザーとの比較を詳しく説明するデータを持つことは決してありません。 ウェブサイトのパフォーマンスがインターネットのクロスサンプリングと比較する方法を理解する簡単な方法の1つは、わずか3つのステップを取ります。
- ドットコムモニターの ウェブサイトスピードテストなどのツールを使用して、サイト上でWebパフォーマンスベースラインを実行します。
- HTTPArchiveのツールを使用して上位 100 または上位 1000 の Web サイトでクエリを実行します。
- httpsArchive.org
- データを比較して、業界に対してどこに立っているかを確認します。
これにより、一般的な Web パフォーマンス分析と平均に関する優れた洞察を得ることができますが、詳細を掘り下げることはできません。 HTTP アーカイブによってキャプチャされたデータセットは、400 GB を超える巨大なデータです。 ただし、ページの読み込み時間からミリ秒を削って成功する場合は、可能な限り最も多くのデータにアクセスする必要があります。
指先での Web パフォーマンス分析
現在、完全なHTTPアーカイブデータセットは、開発者や比較分析に興味のある人がクラウド内のビッグデータを分析できるGoogleツールBigQueryで利用可能になりました。 ユーザーは、巨大なデータセットに対して SQL のようなクエリを実行し、数秒で結果を取得できます。 これで、詳細な Web パフォーマンス分析データを掘り下げて、ウェブサイトのパフォーマンスに関する洞察に満ちたニュアンスを見つけることができます。 まだ試していない場合は、見逃しています。Web パフォーマンスの数値を心の内容に詰め込み、サイトがミックスに適合する場所を詳細に分析できます。
たとえば、膨大なデータセットに対して本当に基本的なクエリを実行し、結果をすぐに受け取ることができます。 次のクエリで、最も人気のある上位 10 のコンテンツ配信ネットワークを特定するために 1 つのクエリを実行しました。
[note note_color=”#e7e7e7″]CDN を選択し、カウント(cdn) を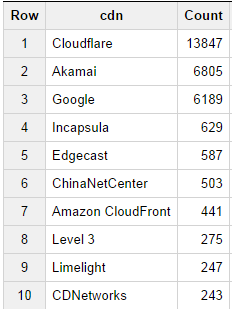 [httpsarchive:runs .2014_09_01_pages] どこから cdn < > “” グループ化してカウント・デスクによって cdn をグループ化します。[/note]
[httpsarchive:runs .2014_09_01_pages] どこから cdn < > “” グループ化してカウント・デスクによって cdn をグループ化します。[/note]
これは次の結果を返しました:
最も参照されている CDN について考えるとき、一般的に最も参照されている資料 (分析用のトラッキング コードなど) をホストしているサイトを考えたため、次のクエリを実行してこの情報を取得しました。
[note note_color=”#e7e7e7″]ドメイン(req.url)Most_Referenced、カウント(*)合計を選択します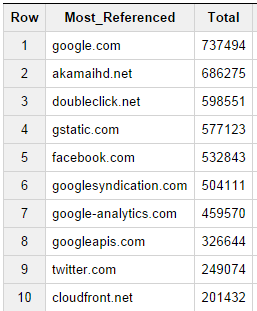
[httpsarchive:runs .2014_09_01_requests]req 結合としてから (
ドメイン(url)自己、ページIDを選択します
差出人 [httpsarchive:runs .2014_09_01_pages] ) をページ上で表示します。
ドメイン(req.url) != ページ.self
グループ化Most_Referenced
総注文数;[/note]
当然のことながら、Google、Akamai、Amazonクラウドフロントがコンテンツのホストと追加の参照要素の両方として広く使用されているため、両方のリストに先駆者が表示されます。
このデータは誰にとってもそれほど驚くべきことではないかもしれませんが、これらのクエリは本当に氷山の先端に触れるだけです。 より複雑なクエリを記述して、Web パフォーマンス分析データを実際に掘り下げ、最も関心のあるパフォーマンス メトリックに関連するコンテンツを特定できます。
さらに良いのは、スプレッドシートをそのビッグデータ処理能力のフロントエンドとして使用できることです。 BigQueryは Google ドキュメントと連携し、上司や興味のある同僚などと、結果をすばやく簡単に表示して共有できるようになりました。
ここでは、昨年VelocityでGoogle開発者の支持者イリャ・グリゴリックからの 素晴らしいビデオ は、BigQueryでHTTPアーカイブデータを使用し始める方法を正確に詳しく説明しています。 忘れないでください: 最初のステップは、独自の Web パフォーマンス分析をインターネットの他の部分と比較するためのベンチマークを持っている、独自の Web サイトのベースライン Web パフォーマンス テスト を取得することです。